The third article of the series of 5 articles describes my journey to build an Engineering setup in Financial Services. Read the preface.
- Building and scaling Engineering team: Principles and practices adopted to build the product and engineering team
- Technology choices & Engineering practices: We took an outward-in approach to establish the foundation of technology stack, architecture/design choices & engineering practices
- Platform Engineering: A team responsible for architecture reference, engineering tools/ practices, cross-cutting-concerns, DevOps processes, playbooks. Provide platform-as-service to the internal product team.
- Infrastructure: The core principle was IAC (Infrastructure as Code). We built a service-oriented structure with Infrastructure as Service
- Operations - keep the lights ON aka DevOps: Traditionally, financial services have a dedicated operations team. Following DevOps principle, we followed – You build it, you run it!
Distributed application and system architecture have increased the complexity of building, testing and, running software and hence, responsibilities for feature development squads increases manifold. There is a dire need for a squad that is responsible to anchor and off-load these responsibilities aka everything outside of feature development to their backlog.
Birth of Platform Engineering Squad (aka Anchor Squad)
When we started to build DKatalis Engineering setup, there was a need for a squad who would own, drive and enable the feature or product development squads with capabilities, for e.g.: CI pipeline, reusable modules (I call them cross-cutting-concerns), boilerplate code modules to name a few, frameworks for performance or automation test suites - the list grows based on how much reusability you would like to introduce.
Hence, we established the Anchor squad (later they named themselves Mars) who were tasked to own these responsibilities including creating/ guarding the blue-print of architecture & design of the near-end-state. The early members of this squad had: Jayendra Patil, Srilekha Misra, Jeevan D C, Mahesh Haldar, Rashmi Ranganathan & Vibhav Gulati
Before we get into details, let’s first understand what is the meaning of Platform and Platform Engineering.
What is a Platform
Platform, as explained in the article from Martin Fowler's post, is a broad term and it has different meanings based on context. But, in the context of software and complexities around building a distributed application, I define it as:
A system or a collection of systems & processes that abstracts the lower level complexities of operating (building, running, monitoring, maintaining) a distributed software & infrastructure setup, enhances developer productivity/ efficiency and decreases time-to-market.
You have to make sure, platform (a product with internal feature developers as audience) has a business value, and anything that impacts the smooth working of the platform should be taken as high priority (similar to how a CX is important). In essence, a platform team is glue between feature developers and infrastructure team with the following:
- engineering accelerators (e.g.: pipelines, templates, container-cluster, automation frameworks)
- cross-cutting concerns (reusable libraries, modules)
- tools/ products either open source or licensed (APIGW, Identity System, Messaging system)
- devops processes
- effective incident management
The Team that manages platform components
Aligning with our 5th guiding principle: Build X-as-a-service mindset, the platform team serves as PaaS internally.
For us, they are also, guardians of architectural reference and innovation (members of architecture guild) and Gate-keepers of tech-stack guard-rails.
Since, we were working for Financial Services setup, as per regulation, we must do yearly DR Swing process - in short, all the services should run in a DRC environment for a defined period. PE squad is also responsible to anchor the DRC process - Infra and services.
The below picture represents the breadth of their responsibilities.
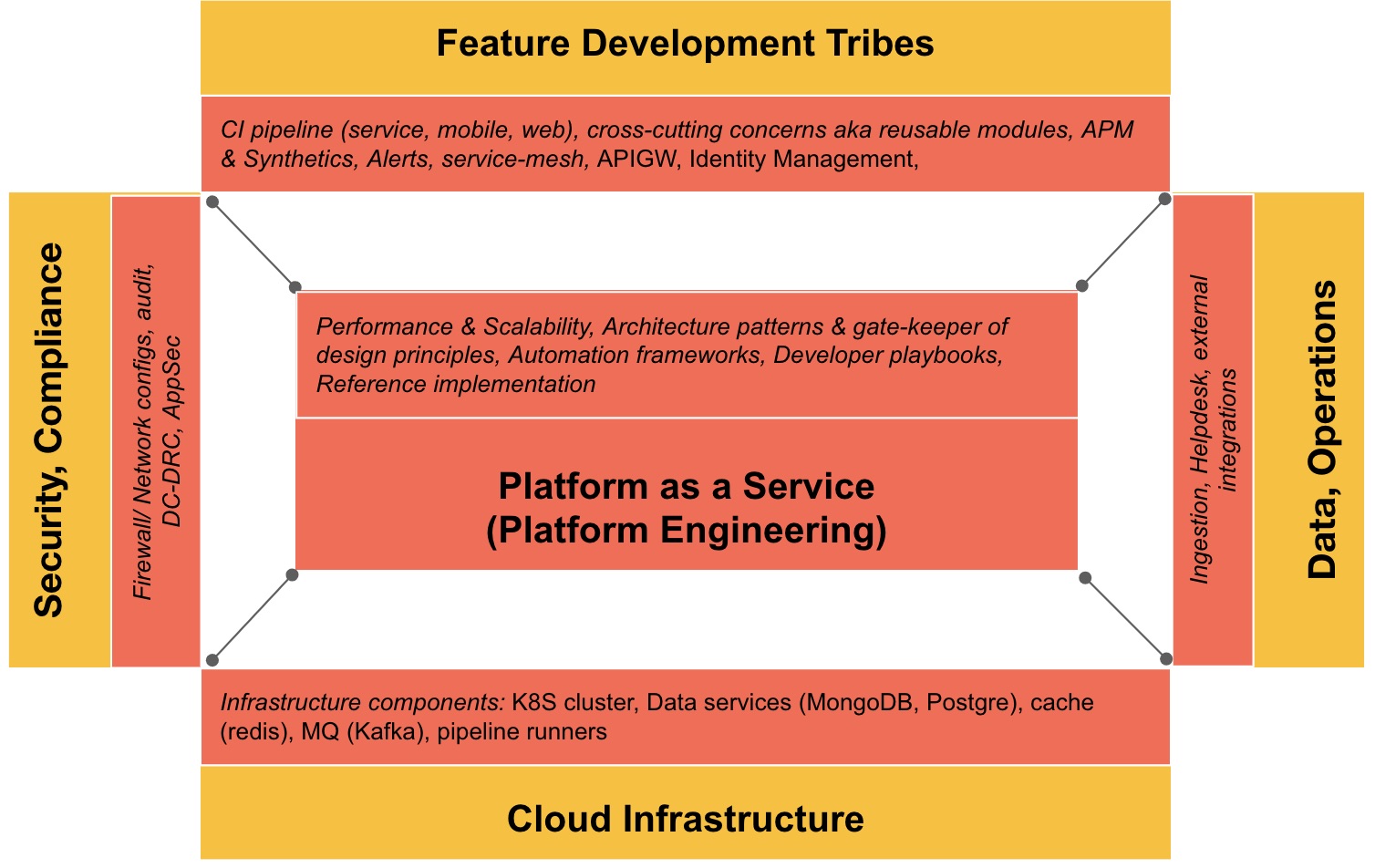
How this fits into Tribes and Squads
If you look at the picture below, there are a few other supporting squads that worked together to support the smooth functioning of Feature development tribes and squads - each supporting squad providing specialised capability to improve productivity and reduce time to market.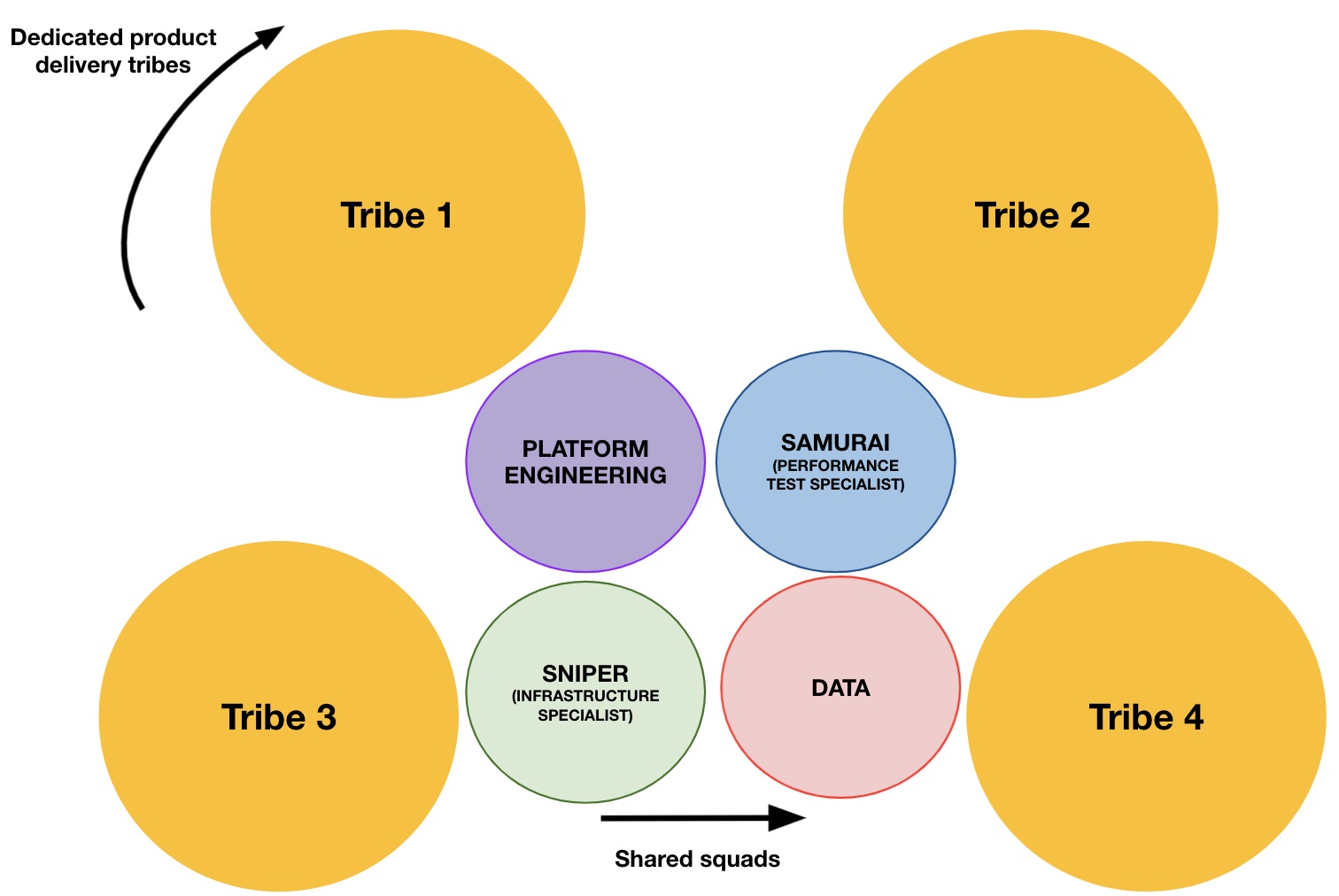
Is this an anti-pattern (against DevOps policy of cross-collaborative teams)
In my experience, many setups don’t realise the amount of work needed beyond having a cloud provider - complexities of managing a distributed application in Prod and lower environments. Hence, PE team becomes a necessity but you’ve to be careful to avoid silos. We faced this challenge as PE became the nucleus and no other squad wanted to own the responsibility of collaboration.
I am a big fan of Linux philosophy: Single responsibility principle, hence, if we follow this principle, having a dedicated set of software engineers to work without interruption on big, complex problems becomes important. They are focused on introspecting the entire software development lifecycle to reduce the shipping time to production.
Guiding principles
- Platform will be treated similar to end-customer facing product: all the metrics that is applied to a end-customer facing product is applicable to internal product/platform - this includes engineering practices, operational practices (Uptime score, Production support)
- Platform components won’t be built without a need: never spend team’s bandwidth building an internal product/platform without a need (on in anticipation). Have a product manager responsible for managing the backlog for Product/Platform
- Designed for TTM: business landscape changes very often, build the platform in a way that gives maximum TTM for feature development team
- Should be Do-It-Yourself: all platform components should be designed keeping in mind - self-service. Engineers should be able to use it themselves without hassle of integration (developer-experience or DX). Platform team would do sufficient documentation and write enablers for DIY. This also means Automation is at the core of all the products created by PE team.
- Internal Open Source: platform components are internal open-source, anyone can extend and add their feature-set as long as they follow defined guidelines. The authority to merge the extended feature is with the platform team.
- Build for ease of evolution: mak sure platforms is designed to be loosely coupled. It enables evolution at the fringes of existing capabilities without impacting existing ones. As a result, we can add more and more capabilities very easily to a platform.
- Uniformity of tools and experience: platform can be used to build a variety of customer-facing products. Design platform which all have a unified developer and user experience.
Learnings & some word for caution
- Platform and Architecture focus early 👍 - start with platform engineering mindset, give enough runway for them to create reference architecture (near-end-state), boiler-plate cross-cutting-concerns (error/ exception handling, adaptors, utilities etc), setup pipelines, quality measures, playbooks, automation frameworks. With these capabilities as a starting benefit, feature squads can maximise their productivity - focus on building strategic components.
- Organisation support is needed to build platforms and teams 👍 - make sure backlog for platform teams are treated with similar level of priority as customer-facing product teams. This is crucial since customer-facing product is running on top of platforms, so, any issue with platform will have blast effect to all products. This would also mean, all engineering practices (git philosophy, pipelines, test coverage, performance/security, scalability, observability) equally apply to all platform components.
- Hiring and capacity 👎 - PE team needs people with specialised skills (engineers who can work on FE, BE, infra, non-functional). In essence, platform engineers are typical software engineers, preferring to work without interruption on big, complex problems. Although, we started with a strong PE team, our focus shifted towards customer-facing product and hence, we couldn’t add more capacity but still a healthy team was there to help flourish feature developers.
- Avoid building siloed expertise 👎 - this was one of the many challenges we faced (still being solved). Since PE team played anchor role, they had the responsibility to collaborate & educate feature developers. We found, platform engineers increasingly spend time educating feature developers on best engineering practices and how to’s of the platform. With more dependence on PE team, the expertise got siloed in PE team. One of the ways to solve this is to embed a PE member into the feature squad for a brief period for coaching on the job.
- Platform team is not SRE 👎 - following the devops model, each team was responsible for building and running their respective systems on production. However, platform engineers were empowered with additional authority/access to production. Very soon, this became and anti-pattern, PE folks started to be seen as first-line-of-defense for production (or for any other environment). It took us a long time to realize, this is burning out PE and moving their focus away from platform components. SRE get an adrenaline rush with solving production outages, platform engineers prefer to operate on a consistent cadence (like other software engineers).
The next article is on how we established Infrastructure as a Service team – we call them Snipers.
comments powered by Disqus