The second article of the series of 5 articles describes my journey to build an Engineering setup in Financial Services. Read the preface.
- Building and scaling Engineering team: Principles and practices adopted to build the product and engineering team
- Technology choices & Engineering practices: We took an outward-in approach to establish the foundation of technology stack, architecture/design choices & engineering practices
- Platform Engineering:A team responsible for architecture reference, engineering tools/ practices, cross-cutting-concerns, DevOps processes, playbooks. Provide platform-as-service to the internal product team.
- Infrastructure: The core principle was IAC (Infrastructure as Code). We built a service-oriented structure with Infrastructure as Service
- Operations - keep the lights ON aka DevOps: Traditionally, financial services have a dedicated operations team. Following DevOps principle, we followed – You build it, you run it!
This article covers the aspects of technology choices and practices that govern the build of the software product.
Technology Stack and development tools
As mentioned in the previous article, we are on the bleeding edge of the technology stack.
Optimise for team strength when choosing tech stack
Make sure to have tech stack based on team’s strength and consumer needs. The below table represents the choices we had in place across technology and process enablers:
| Category | Options |
|---|---|
| Technology | |
| Cloud Provider | GCP |
| Databases | MongoDB, PostgreSQL |
| Source Control | GitLab |
| IAC | Terraform, Ansible, Helm |
| Compute Engine | GCE |
| Containers | Docker, GKE |
| CI/ CD pipeline | gitlabCI, Bitrise |
| Languages | Dart (Flutter), JS (nodeJS) |
| Short cache | Redis |
| Firewall | Cloudflare |
| CDN | Cloudflare |
| Code Quality tool | Sonarqube |
| Automation | Dart, JS |
| Service Communication | Kafka |
| APIGW | Tyk |
| Identity Management | Forgerock |
| Secret Management | Vault |
| Logging | ELK, GCP Logging |
| Monitoring | Dynatrace, Cloud Ops |
| Alerts | Pager Duty |
| Performance | jMeter |
| Process Enablers | |
| Agile | Jira, Confluence |
| Collaboration | Slack, Gmeet |
| Project Management | Smartsheet |
Airbnb changed their FE stack to optimise for team productivity
The anti-pattern
There is an anti-pattern here, we chose Flutter as our FE stack, even though, we didn’t have anyone in the team that had worked on Dart before. The driving factor for this decision was CX - we wanted to have single-code across all channels/ platforms and hence, ReactNative was our first choice, however, the customer segment we were serving had very low-end smartphones (need for native apps). Dart was a good choice and my chat with Chris Sells put a stamp on the decision.
Development practices
I consider good Engineering practices as enablers for building & shipping quality software that helps businesses and customers be successful. (there is no value of writing code that doesn’t make business successful). So, always focus on a pragmatic approach that is needed for a successful product launch.
Engineering practices do not need an introduction:
- Write testable code with test coverage
- Run the build and tests in a CI process
- Use test pyramids. Read this wonderful article by Martin Fowler
- Build once, promote further (deploy automatically or by the click of a button)
- Error and exception handling (system, business, integration)
- Make your systems Observable (and auditable)
- Performance and Security are features in the backlog (took a lot of time for us to bring this practice in-place, still WIP)
- Infrastructure and configurations are code (run them in a fully automated pipeline)
- TDD, Code refactoring, architecture/design discussions are mandatory (among these TDD is still WIP)
- Use metrics to measure (extension of DORA)
Like always, we created some guiding principles, some highlighted ones:
Guiding principles:
- Blue-print the near future state: always create the near end-state of application architecture (or the blue-print) as reference. Remember, your end-state will evolve but it is important to have a path and track the progress.
- Align architecture and design principles: As you scale, to avoid choking design decision-making, it is important to have it distributed but we made sure there is an alignment of the ones we care the most:
- Reusable (don’t reinvent the wheel) and Single source of truth (master)
- SRP & YAGNI (these are my favorites)
- Keep in-mind x-as-a-service
- Secure service
- Design for Async (least coupling)
- Invest in building cross-cutting-concerns (do a very early investment): this is the basis of the Platform Engineering post
- Reduce entropy - make architecture composable
- Organize code and pipelines (automate all components, everything is code including configurations)
- Version code/ APIs (use Semver). Document APIs (we used Redocly)
- Write single code for all customer channels (feature parity becomes a big challenge across various channels). We chose Dart (Flutter)
- Follow test pyramid (invest in automation but remember it doesn’t solve all testing problems, you still need to do manual testing. Follow measuring ROI)
- RFCs and ADRs are a must: when should you write an Architecture Decision Record. If you’re interested more, read Git Architecture — a better way to capture Architectural decisions by Kyle Gene Brown.
- De-couple deployment and release. Feature flag them
- Deployments should be as per schedule (we deploy to production at the end of each sprint). Frequent deployments
reduce the blast radius - Enables capabilities for Canary deployments with sophisticated
Feature Flags - Feature release is driven by the Product Team based on: feature completeness or other strategies
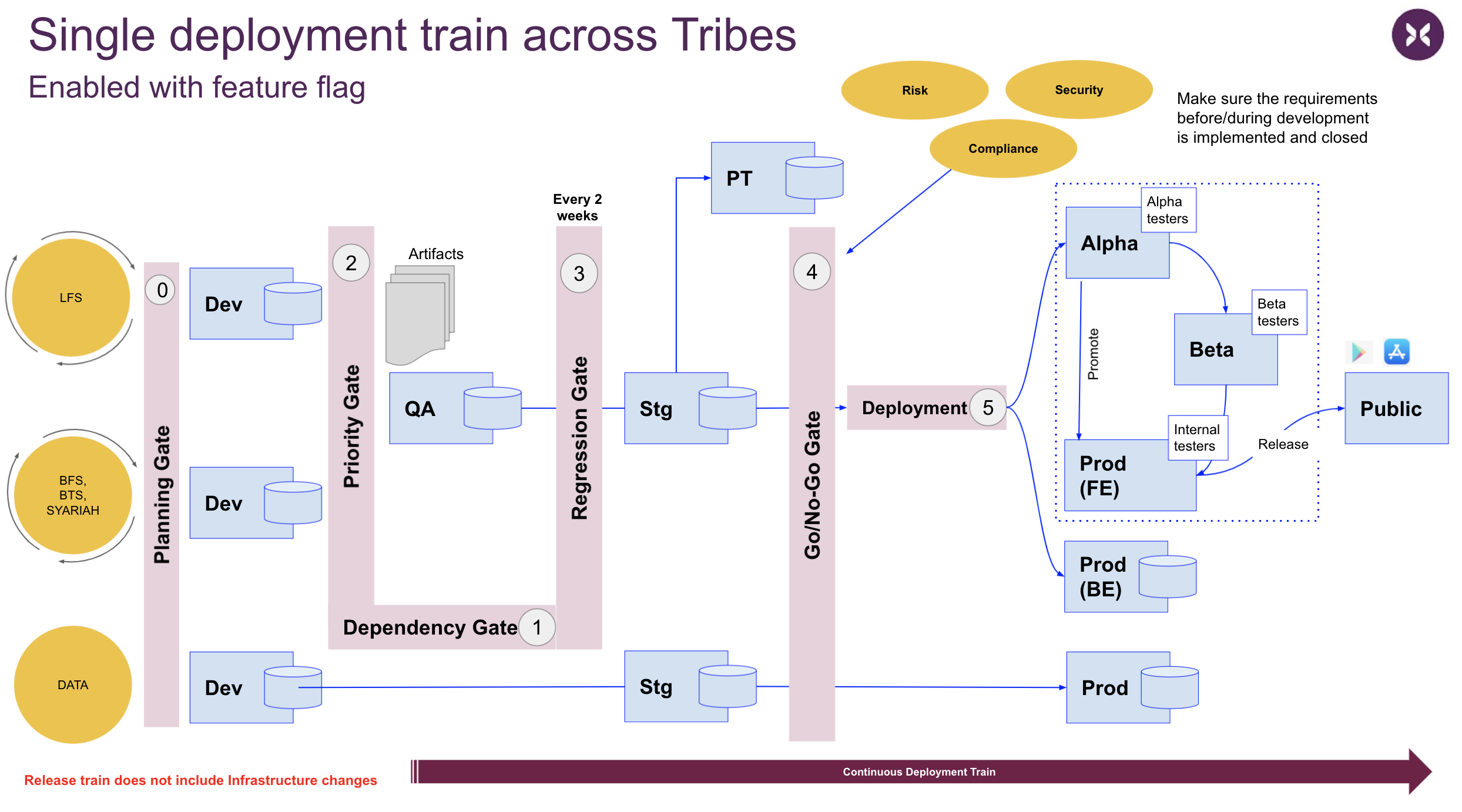
Deployment & Release Train
- Deployments should be as per schedule (we deploy to production at the end of each sprint). Frequent deployments
- Follow deployment train: we have a strict cadence of deploying working software at the end of each sprint: development, test, validate performance and deploy (as depicted in the picture above). Squads can choose to catch or leave the train based on the readiness of their feature.
- Design for failure
- Backward compatibility is a must: Make sure infra, application modules, APIs are all backward compatible. Use
Semverto version your software. - Make systems and applications Observable: Make your application and systems monitored proactively - you should know before customer experiences downtime.
- Backlog is the single source of truth: Everything should be in the backlog (functional features, non-functional requirements). Make the backload measurable so that team can predict on the time to churn.
- Define engineering metrics and track them: One of the life lessons -
if you have to manage, find ways to measure
Hence, to measure various aspects of our Engineering setup, we defined metrics across various dimensions:
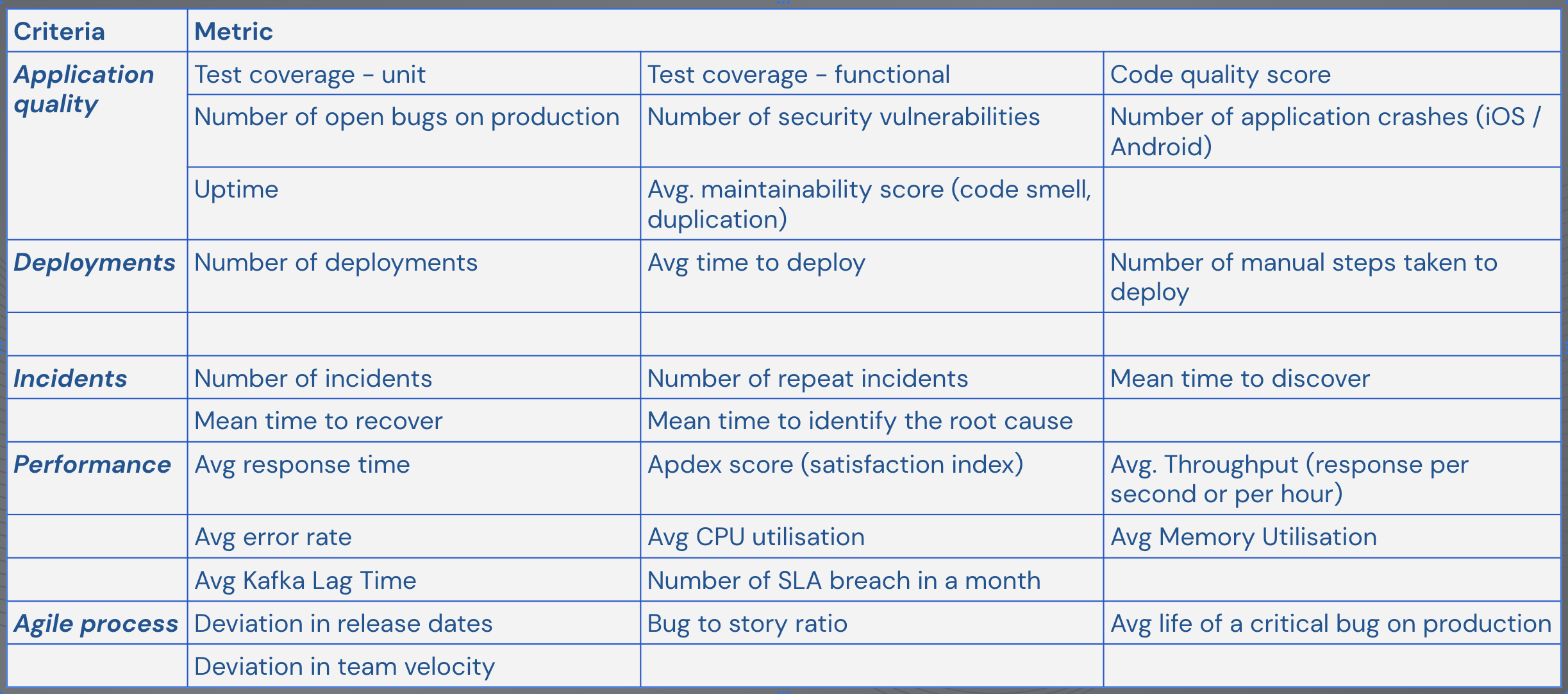
Metrics are categorised across Application Quality, Deployments, Incident Management, Performance and developmental process. If you notice closely, most of these metrics are inter-dependent e.g. deviation in release date and velocity are closely linked. Additionally, the data for measuring these metrics is spread across various systems:
- Jira/ Confluence
- Sonarqube
- Monitoring across tools like Dynatrace, Cloud monitoring
- Gitlab runners
- Crashlytics
- Incident management
- Pagerduty
We developed our in-house tool that assembles data from all the above and creates aggregated charts. This is a WIP progress system and it is one of the crucial’s to keep a close track.
Aspects of development practices
As far as it goes with me, there are 3 major pillars of software development practices: Predictability, Quality and Automation.
Predictability
Your backlog should be the source of truth for any task the developers do. Enforce to make sure this gets strictly followed, even if it is not related to writing code (make sure tickets are tagged, so that you can accordingly measure time spent outside of writing code). All public releases should be based on churn-rate of the backlog - this helps the product & GTM (go-to-market) team plan feature releases.
The anti-pattern: Prioritise initiatives that are dependent on multiple squads
We faced a similar challenge - the feature had multiple squad dependencies and priorities need to be worked on. There are various ways to solve this, however, the one that has started to work for us: single backlog across all squads. Make sure you have one single backlog, it helps to bring one single view of features and henceforth easier to prioritise. It also helps to make cross-squad dependency visible for better management. One of the other ways, I have seen this working is through vertical slicing of features — reducing cross-squad dependencies but in a distributed system setup, this is rather difficult to implement.
Quality
Quality doesn’t need an introduction but I will focus on one aspect of the software process (which is very close to me) - testing. I consider testing and people related to them as First-class citizens. In our world of complex, distributed systems, testing is vital to reduce the risks of downtime and disruption. Testing is the responsibility of the whole squad, not only our testers. In essence, our QAs are gate-keepers of quality that get delivered from the squad.
Remember, when something goes wrong on production, the first thing that people question, did we do proper testing?
We celebrated testing as one of the important ceremonies in our Agile process — it is one of the thankless & a monotonous activity. This is still a WIP and our major tech debts are around automated testing. We are doing investment to build boilerplate code of automation frameworks so that team can focus on writing better and maintainable test scripts.
The anti-pattern: Quality vs speed of delivery
Having worked with various teams, I have started to believe, speed of delivery has not only dependence on baking quality (aka testing: functional or non-functional) but also on other aspects: feature clarity, time spent by developers on poor design decisions than writing the feature, time spent in regression test cycles or time spent in managing dependencies. Closely monitor the time team spends not writing software, it will bring out hidden avenues to improve speed of delivery.
The anti-pattern: Deadline driven development
There are situations where you have to choose speed over quality — it should be done only in situations where you’re getting a competitive advantage. I must warn you here, be careful, otherwise this becomes a norm and you’re bitten by what I call: Deadline Driven Development. In such a scenario, team is doing a constant death march.
Automation
Automation should be the basic requirement to any manual process followed during feature development, build, testing or deployment.
a step that requires to be done with an executable command more than 3 times, should be automated
we followed the about guiding principle across. It took time (still needs constant pushing) to build a mindset of automation. Be lazy, be hungry to automate, be a blocker - all these were simple radiators that we constantly pushed through the organisation.
Engineering cadence and forums
Having cadence and a regular touch-point becomes an important aspect of communication flow across the organisation. We enabled multiple forums to have information flowing related to OKR and technical design discussions.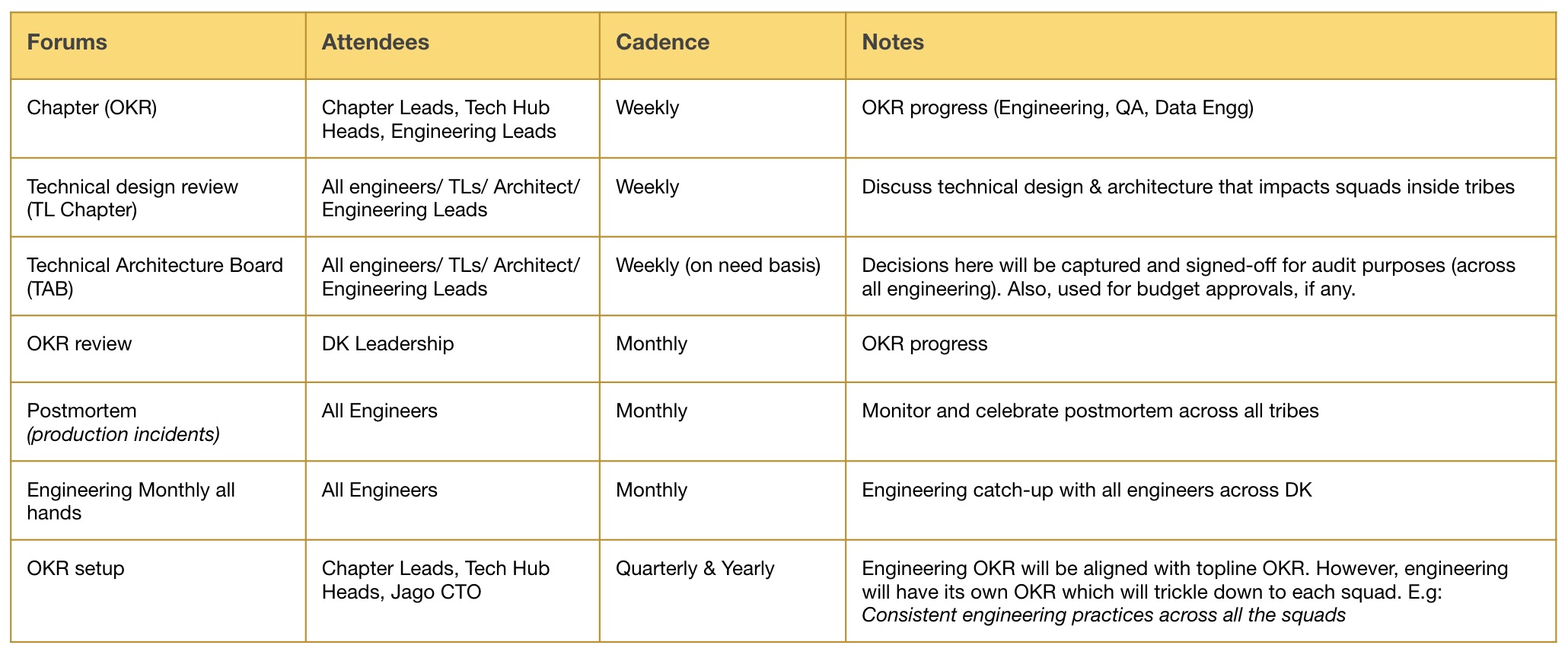
Each one of the above forums has relevance based on the frequency we followed.
Read through the next article on Platform Engineering.
comments powered by Disqus