The first article of the series of 5 blog posts describes the journey to build an Engineering setup in Financial Services. Read the preface to get a clear context of the journey.
- Building and scaling Engineering team: Principles and practices adopted to build the product and engineering team
- Technology choices & Engineering practices: We took an outward-in approach to establish the foundation of technology stack, architecture/ design choices & engineering practices
- Platform Engineering: A team responsible for architecture reference, engineering tools/ practices, cross-cutting-concerns, DevOps processes, playbooks. Provide platform-as-service to the internal product team.
- Infrastructure: The core principle was IAC (Infrastructure as Code). We built a service-oriented structure with Infrastructure as Service
- Operations - keep the lights ON aka DevOps: Traditionally, financial services have a dedicated operations team. Following DevOps principle, we followed – You build it, you run it!
How we started
DKatalis is an engineering setup and hence, we had our tech stack on the bleeding edge for Financial services - Dart (Flutter) for FE, server-side JS (NodeJS) for BE, Kafka (service communication and data streams), APIGW (Tyk), MongoDB, Redis, CloudFlare, ELK, Dynatrace & Solarwinds, Terraform (IAC) & full cloud setup to just name a few.
Starting to build a team without a brand name is challenging, it starts with your network and expands to layers beyond. Add to it, the bleeding edge of technology (especially Flutter, we couldn’t find experienced engineers in the region, more on this later), making it even hard to build the team.
As explained in the preface, guiding principles are important. Hence, the first step for us was to have guiding principles which will be used to build the team. With help from Maya Kartika (our Head of People) & Ivan Vincentius (Head of Jakarta Hub), we came up with the following principles:
Guiding principles:
- build the team where it is needed
- build the team where talent is available
- responsibilities are more important than titles (senior members will have a broader set of responsibilities)
- build a balanced team (mix of senior, mid-level & juniors). This is still a struggle for us
- people are assets, invest in them (it’s a journey and we are making progress here)
With the above guiding principles, it was clear, we need to hire engineers outside of Indonesia (although our core business team was in Jakarta). We started the process to establish entities across 3 locations: Singapore, Jakarta & Pune. Not going into details of an entity setup, assembling a diverse & geographically distributed team is tough. The first step was to hire a few good tech recruiters and build a network with head hunters. We started with initial 7-8 core members who started to: build the foundation and also invest time in hiring.
You need to do early investment to build your brand equity - this becomes even more important if your brand is not an established one. Initially, the slow response was slow but with efforts from our recruiters, engineering staff, and our Tech Hub Heads - Ivan Vincentius & Puneet Jain, we got good results. We grew from 10-12 members in Oct-Nov'19 to 200+ in Dec'20 across the 3 locations – Singapore, Jakarta & Pune (as of the date we have 300+ across the locations).
The hiring process
The hiring process should reflect what kinda team you want to build. Going back to our guiding principle, we wanted to have everyone hands-on, this meant,
no matter years of experience, every candidate would have to go through a test exercise
Hence, we configured the hiring process to make sure it reflects the type of team we want to build.

The same process was configured for all the roles: Product Engineers (Developers and Automation Engineers), Platform Engineers, System Engineers (Infrastructure), POs, Security Engineers, Performance specialists, Data Engineers, Data Science & Data Analysts. This not only helped to keep a consistent hiring process across the organisation but also in propelling a culture to be driven by responsibilities.
Principles for hiring
- Make sure to draft the roles and responsibilities for each profile (aka JOb Description)
- Strictly follow the hiring funnel
- Reduce subjectivity in the process
- If in doubt, reject (letting go someone after hiring will be expensive)
- Keep track of the hiring funnel, fine-tune the process
When you are starting, interviews are the first impression to candidates (and their network of people) about the organisation. Make sure your recruitment team and panelists are Brand Ambassador of the company, make Candidate Experience, the first thing to focus.
We did this by reviewing and documenting, each stage of the interview - from recruiters and panelists perspectives:
- how to engage with the candidate (outside and during the interview process): intros, pitch about ourselves, explain the hiring process, pause between questions and invite them to ask, explain about the assignment and the review process, confirm the role he/she has applied
- scheduling interviews: recruiter needs to ensure both candidate and the panelist are available. They would do an initial intro before the interview starts. If the interview cannot happen, avoid last-minute changes
- how to conduct the interview: follow guidelines for each stage of the interview
- during the interview: respect the interview time window (review the feedbacks from previous stages and prepare), summarise your understanding (don’t assume), be aware of your body language (help them succeed)
- after the interview: fill feedback form with a defined structure, be available to answer queries from the candidate (even if he/she is not selected), take feedback from the candidate, do a panel debrief, if in conflict
As you grow, the hiring panel starts to broaden and hence, the subjectivity during interviews. Even though we documented each stage of the interview process, still we started to see subjectivity (or I must say the drop in quality) in hiring - remember we were dealing with hiring at 3 locations. With retrospectives, we found one of the most challenging stage was code review. Hence, we standardised the code review process. Jeevan D C, Ivan Vincentius and I put clear dimensions for feedback:
- Code structuring (Directory structure, First-class objects, Modularity, Design patterns)
- Engineering practices (Naming conventions, git process/logs, clean coding rules, documentation, tests & coverage)
- Runtime (logical approach, error handling, readme)
Keeping track of the progress
As you continue to build your team, it is imperative to have a regular review cadence of the progress. The intent is to identify blockers for each stage of the interview and identify opportunities to optimize the process. The first step was to capture data - fall out of profiles from each stage.
Waste repellent learning culture - reduce waste, remove unnecessary process
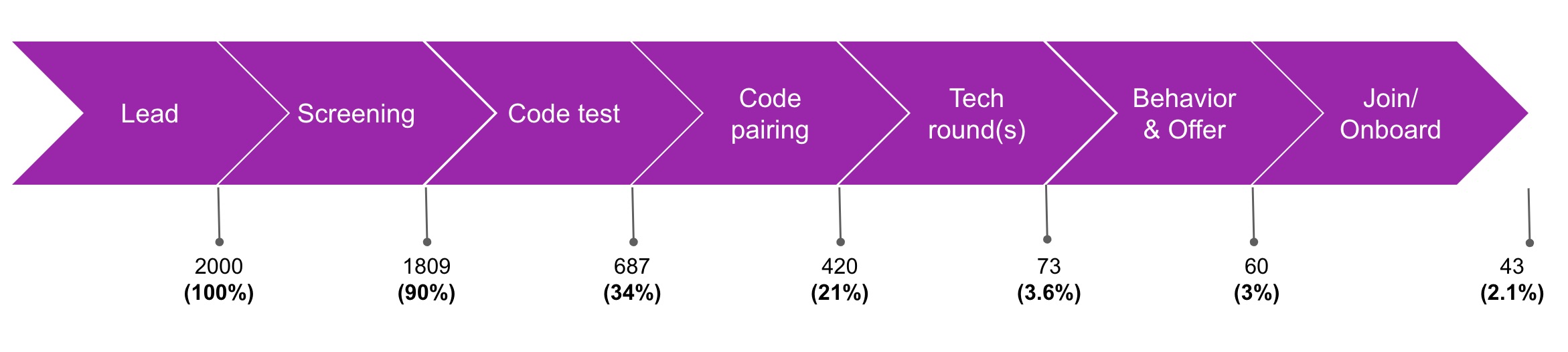
Time to offer < 3 weeks
This metric tracked the time it takes from the first touch-point with the candidate to when the offer letter is sent - measuring the time spent during each stage of the interview. We challenged ourselves to complete the process in not more than 3 weeks. Today, this metric measures 22 days across the location.
Organizing teams
When you’re small, everyone does everything, it was the case with us as well. But, as you grow from 20-100, organizing an agile team is a fundamental problem everyone starts to face. I have been part of designing and building engineering Org structure at least twice so far (Bank BTPN during IT Transformation & DKatalis as we scaled). Like always, we established important guiding principles as our steer the direction:
- Reduce silos & increase Communication: communication plays a fundamental role between squads. As the number of squads increases, communication or alignment between them starts to break. It can be product spec alignment or prioritisation or design decisions or release dependency. Make sure to define processes to have the communication flowing. More the communication, less the silos across squads.
- Decouple Org structure & Career growth: Typically, the boxes of an org structure are seen as the career path of an individual in an organisation. Additionally, the org structure also becomes the reporting relationships that people might love or hate. We chose to detach Org’s structure (keep it flat) and career growth path. We designed the growth path to be based on dimensions of responsibilities: Impact, Innovation & Leadership, while the org structure was focussed on pure building blocks of the company. This is an ongoing task, we are still working and making it fine-tuned.
- Customer centricity: This is a very important dimension of the Org model is value proposition for its customer, employees, investors.
- Team autonomy: Team autonomy is one of the primary requirements for decentralised decision-making. It reduces choke points and increases team productivity. As explained by Henrik, team autonomy is one of the fundamental benefits of the Spotify model. However, as the number of squads increased, we faced challenges in making sure autonomy is not taken as a process to choose anything. We introduced what I call Guardrails around Team Autonomy.
- Productivity: The purpose of an Org structure is to enable engineers to be more productive - reduce blockers, increase collaboration. In the next batch of the series, I explain in detail the Development practices and processes that helped us with productivity.
Tribes-Squads-Chapters
Spotify Model answers most of the guiding principles listed above, hence, it was our defacto choice to organise the team. Having said that, Spotify model doesn’t answer many questions, so, we did not consider –
Spotify model as a framework
– but as guidelines for autonomy, communication, accountability, and quality (as suggested by Henrik Kniberg in his article - No, I didn’t invent the Spotify model).
Organising ourselves in Squads & Chapters
Conway’s Law: Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
In short - communication structure in the organisation directly influences the design of technical systems. So, if we inverse Conway’s Law - for optimal system architectural designs, we have to simplify the communication structure in which, team size plays an important role in socio-interactions. Hence, our choice was to build small X-as-service provider teams knitted together through loosely coupled API communication and customer journeys:
- registration journey
- payment journey
- transfer journey
- partner integration journey
A typical squad is led by a combination of PO and Tech Lead (who are also responsible for the scrum ceremonies). Additionally, a squad will also have FSE - Full Stack Engineers (each specialising in FE or BE) and Quality Engineers (for automation). We tried to maintain a healthy ratio of 3:1 (for every 3 developers, 1 QE) - as depicted below: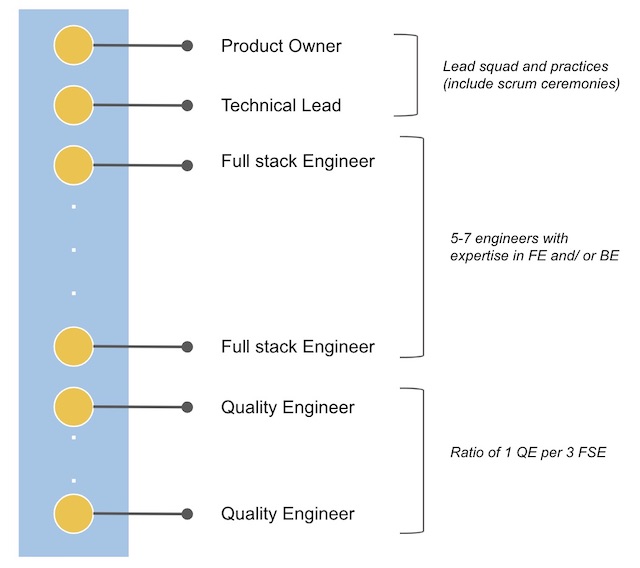
In my opinion, it’s a myth that an Engineer can be an all-rounder - expert in FE, BE and Systems (aka Infra). I prefer to maximise on their strength, make them work as pairs to optimise productivity & quality. (may be an article for future)
The picture below represents the squad/chapter setup we had in-place.
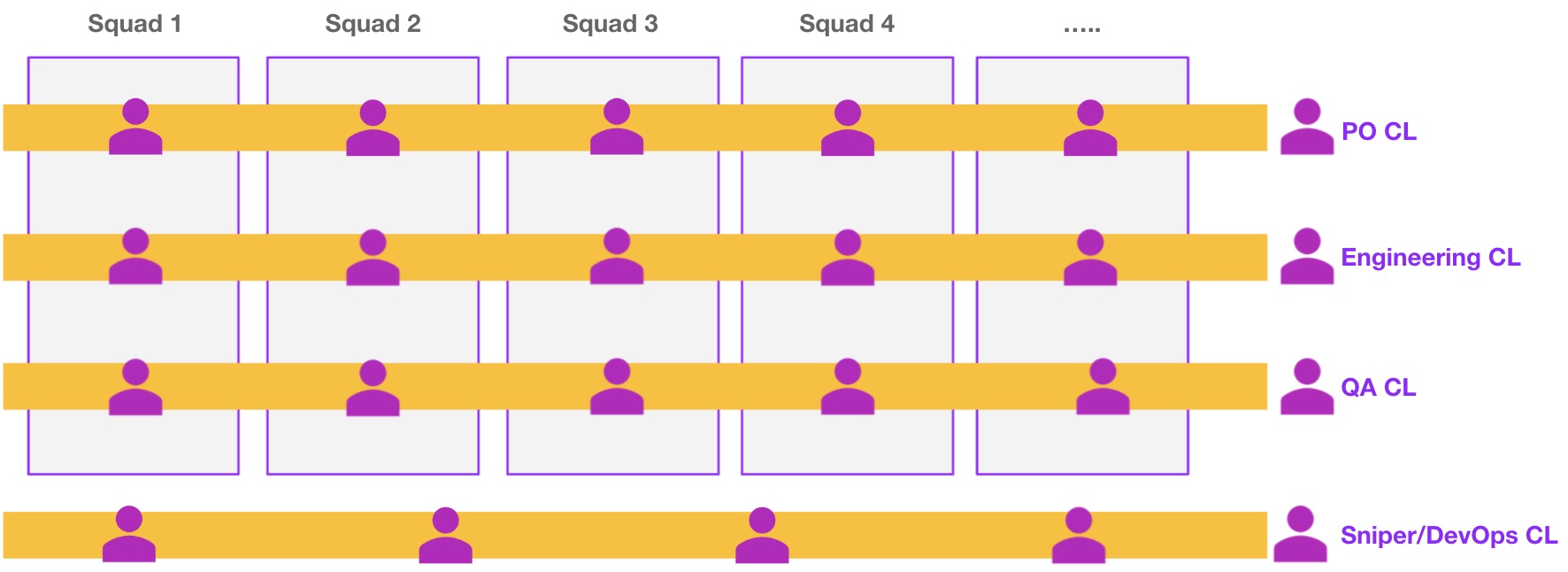
In addition, we built some core squads responsible for specialised work:
- Platform Engineering (more on this in the upcoming post): they are responsible for: cross-cutting concerns, engineering tools/platforms/components that are used across all teams, gatekeepers of scale, reliability, security. In short, they are the glue between Product Delivery and Infrastructure squads.
- Samurai: A specialised squad responsible for managing Automation frameworks, Performance/ Load test frameworks, DevSecOps
- Sniper: A squad responsible for providing IaaS to all other squads. They do: IAC, Infra operations, Monitoring, Alerts.
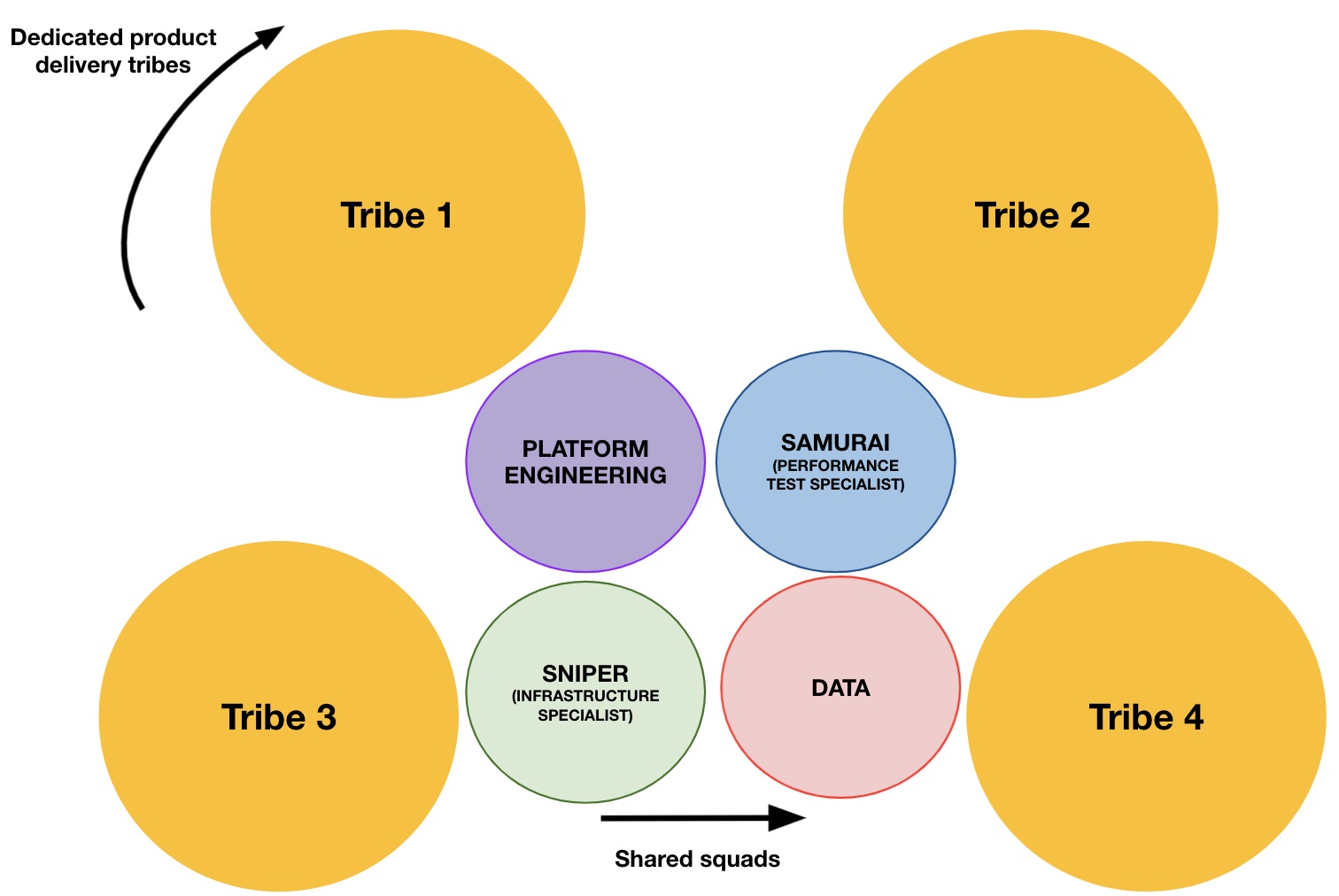
Oragnisation Structure
The upskilling program
Or rather capability building - we designed a number of boot-camps and upskilling programs to make sure everyone is spending time outside of deliveries to learn & grow. Some are listed below:
- best practices for writing good quality software
- good practices for writing stories & managing backlogs (including cross-squad alignment)
- boot-camps for learning Flutter & NodeJS
- how to effectively use OKRs to manage priorities and cross tribe/ squad dependencies
- devops boot-camps
Pitfalls and learnings
Building an engineering setup from ground zero and scaling it to 300+ in less than 2 years was a huge undertaking. For sure, we had many learnings during this journey, some of the important ones to highlight here:
- Build Platform Engineering squad 👍: Do an early investment in shaping Platform Engineering Squad and make sure they have enough capacity as you grow. We did so and hence, we reaped benefits of having:
- reference blueprint of the architecture
- cross-cutting concerns (re-usuable modules & boiler-plate code) were developed before product squads started to write features. This helped in reducing the spaghetti of code duplication and inconsistency across various squads
- focussed attention on non-functional features - performance, scalability, reliability, security
- Hiring mistakes are very expensive - build a balanced team 👎: this is one of the problems that we are still solving. We hired quite a few junior staff, although, we designed boot-camps and crash-courses to bring them up-to-speed, it still takes time for them to be productive independently
- Avoid cross-squad feature split 👌: As far as possible, do a full vertical slice of feature to a squad (FE, BE, Systems, Operations). Distributing it across multiple squads leads to un-necessary project management overheads
- Chapters should be tightly integrated with the Product Backlog, otherwise, chapters would just be on paper 👎
- Measuring the productivity of squads is a trap, rather focus on outcomes they are producing:
- You should never compare the velocity of multiple squads (this is a well-known fact) but we end up doing that. Very soon it becomes a number game and the squads will start to blow-up story points to match up velocity (👎)
- Define metrics to measure outcomes:
- quality metrics
- time to ship a feature
- incidents or bugs found on production
- bug to story ratio
- life of critical bugs on production are good examples of outcomes produced by squads. In the next article, I would walk through categories of such metrics.
- Have a regular cadence of sessions with the whole Organisation 👌: share the larger picture, celebrate successes & learnings
- Designing career path/ growth is tough 👎. Do an early investment
People talk a lot about Engineering culture, however, my strong belief is:
practices followed in the organisation get into DNA and hence become the culture
Ending this article with the statement
Engineering culture (or rather any culture) is an outcome of practices
I would like to hear your thoughts on Engineering Culture. (more on this in a separate post)
I hope this article was an interesting read and provided good insights on our journey building an Engineering team.
comments powered by Disqus